The MSToolkit comprises a suite of low-level functions which are used to generate data and apply user-specified analysis functions or SAS analysis code to the generated data. High level functions are provided which wrap these functions together to perform the data generation and analysis steps.
The generateData(...) function calls the low level generate data functinos to create sets of simulated data. The following components are called to create aspects of the simulated trial data:
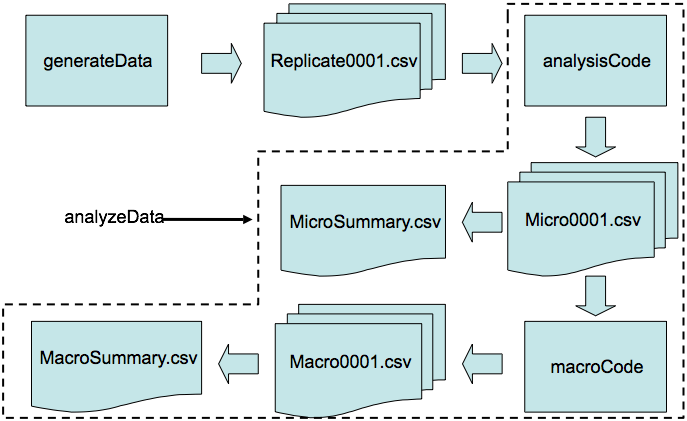
Most users will start with the generateData(...) function which uses the functions described above to specify the design, allocation to treatments, generation of parameters, functional specification for generating data and controlling dropout and missing data. The function has a great number of arguments which control and pass information to the low level functions. Most of the time users will not have to dig into the lower level functions. However more complex designs can be generated using the low level functions e.g. Generating data for more than one drug in a trial. The generateData(...) function creates a directory with the replicate datasets stored as individual .CSV files.
Once data has been generated, the next step is to analyse the replicate data using the analyzeData(...) function. This function wraps together functions for performing user-specified analysis on the replicate datasets and also performing micro- and macro- level summaries of the analysis results. Micro-analysis summarises the analytic method at the dose or treatment level, giving the estimated mean, std. error and confidence limits for each dose / treatment and for each interim analysis (if specified). This allows the user to specify a rule for dropping doses or treatments at interim analysis. Macro-analysis summarises the analytic method at a study level, applying a user-specified rule to determine success or failure of the trial for assessing the operating characteristics of the trial. Unlike the generateData(...) function, analyzeData(...) has limited functionality that will be accessible to most users - the low level functions here principally govern the data input and output in the analysis of the replicate datasets.
If interim analysis has been specified in the generateData(...) function (through specifying what proportion of the overall sample size to include in each interim cut) then users must also pass interimCode to the analyzeData(...) function. When it analyses each replicate dataset, MSToolkit will first apply the analysisCode to the complete dataset, then pass through applying to each interim cut of the data. interimCode is a function applied to the output of the analysisCode to determine which doses are to be dropped, or whether the study is to terminate at that interim. By first applying the analytical method in analysisCode to the complete dataset we can compare study outcomes in the presence and absence of interim analysis decision making. At each interim analysis, data from doses that are dropped are excluded from the following interim cut datasets, but existing data on those doses is carried forward into subsequent analyses.
MSToolkit creates a directory called "ReplicateData" under the current R working directory for the output from the generateData(...) function. The individual replicate datasets are stored in comma-separated variable (CSV) format in this directory and are named "replicate000x.csv". Up to 9999 replicate datasets can be created. MSToolkit creates two directories called "MicroEvaluation" and "MacroEvaluation" under the current R working directory for the output of the analysisCode ("Micro000x.csv") and macroCode ("Macro000x.csv") functions respectively. The analyzeData(...) function also collates each individual replicate output dataset into two summary files "MicroSummary.csv" and "MacroSummary.csv" in the current R working directory.